英伟达第四季度财报:市场担忧竞争,但英伟达的护城河远不止于 CUDA


本周市场焦点全在Nvidia身上,该公司即将发布其2026财年第四季度财报。
指标 |
2026财年第四季度预测值 |
同比增长 |
背景信息 |
营收 |
650亿美元 – 658亿美元 |
约67% |
高于2025财年第四季度的393亿美元。反映了Blackwell架构的峰值产能爬坡。 |
调整后每股收益 (EPS) |
1.46美元 – 1.53美元 |
约71% |
较去年的0.89美元大幅增长。 |
毛利率 |
约75.0% |
+140个基点 |
力求从第三季度的73.6%“下滑”中反弹。 |
数据中心营收 |
约599亿美元 |
约66% |
约占公司总营收的90%。 |
NVIDIA 2026财年第四季度的财务预测显示该公司仍处于高速增长期。营收预计在650亿至658亿美元之间,较2025财年第四季度的393亿美元同比增长67%。这一激增主要由“Blackwell”架构驱动,该架构目前已达到产能爬坡的峰值。数据中心业务依然是公司无可争议的增长引擎,贡献了约599亿美元,占总营收的90%。
盈利能力也显示出稳定迹象。调整后每股收益(EPS)预计将跳升至1.46美元至1.53美元之间,较去年的0.89美元大幅跃升。对于投资者而言,或许最重要的一点是毛利率有望恢复至75.0%。此前,第三季度毛利率曾暂时下滑至73.6%,这归因于复杂的Blackwell系列初始良率较低以及45亿美元的库存核销。然而,新的挑战也随之而来:内存价格上涨25-30%可能会对毛利率造成下行压力,在未来几个季度可能产生2到3个百分点的阻力。
在财报电话会议上,投资者还将密切关注有关产品线的任何更新。
代次 |
架构 |
年份 |
GPU型号 |
CPU型号 |
关键进展 |
即将推出 |
Feynman |
2028 |
F100 |
Vera Next |
针对下一波“具身智能”(Physical AI)。 |
当前/未来 |
Rubin |
2026 |
R100 / Rubin Ultra |
Vera(88核) |
HBM4内存、3nm工艺、1.8 TB/s NVLink。 |
最新 |
Blackwell |
2024-25 |
B100,B200, B300 |
Grace (72核) |
首款“双芯片”GPU;集成2080亿个晶体管。 |
传统 / 成熟 |
Hopper |
2022-23 |
H100, H200 |
Grace |
针对大语言模型 (LLM) 引入了“Transformer引擎”。 |
股价触及天花板
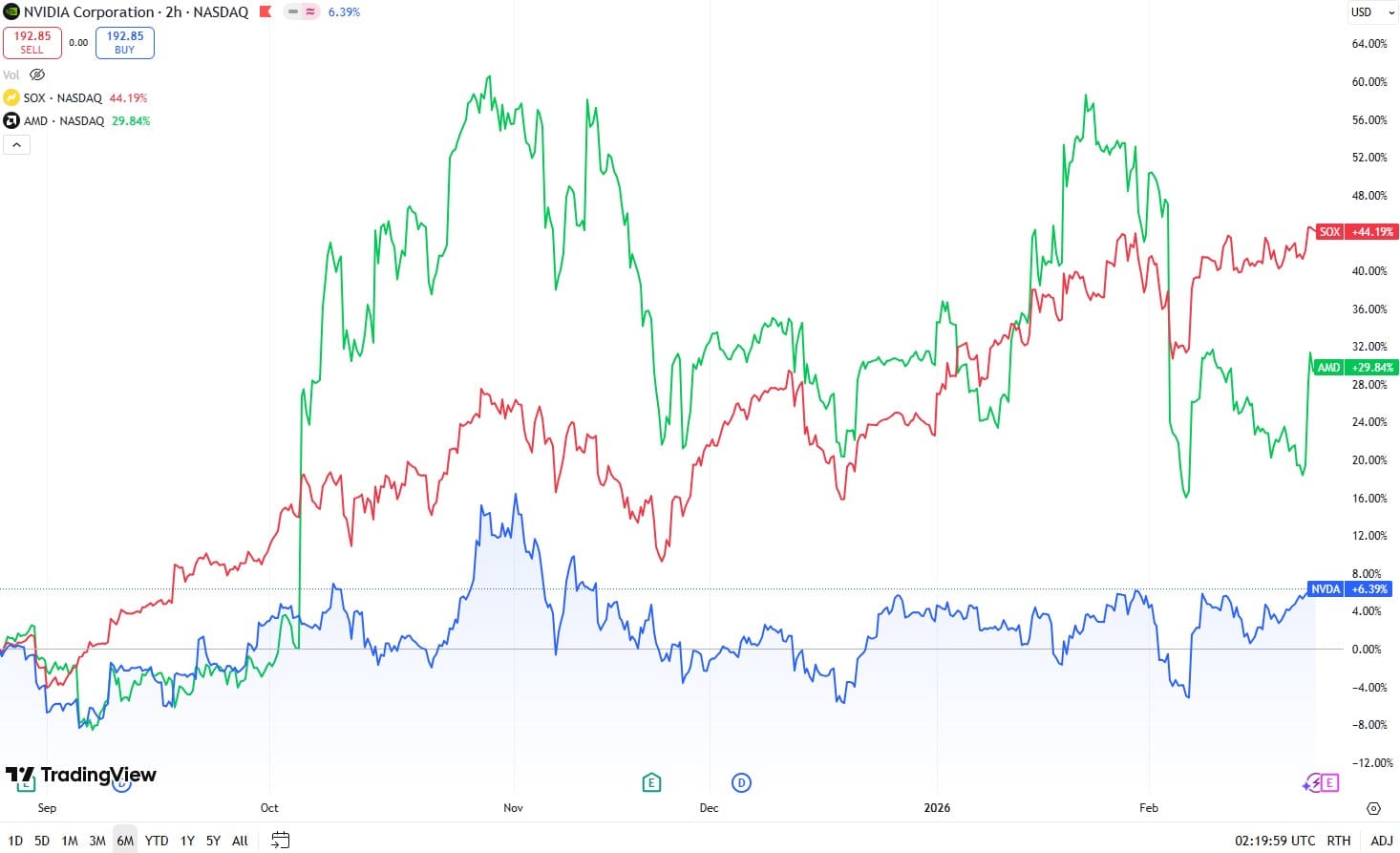
数据来源:TradingView
尽管有这些“令人印象深刻的数据”,NVIDIA 的股价在过去六个月中仅上涨了 10%。相比之下,其主要竞争对手 AMD 上涨了 23%,而同期的 SOX 半导体指数则飙升了 48%。这种表现不佳尤其令人费解,因为“超大规模云计算巨头”——Amazon、Alphabet、Meta 和 Microsoft——均大幅上调了 2026 年的资本支出(Capex)指引。
从逻辑上讲,这些科技巨头增加资本支出应当等同于 NVIDIA GPU 收入的增长。然而,当 Amazon 宣布将资本支出增加 56% 至 2000 亿美元时,NVIDIA 的股价却持平。在 Alphabet (+98%) 和 Meta (+74%) 大幅上调指引后,市场也出现了类似的反应。
公司 |
2026 年资本支出指引 |
同比增幅 |
NVDA 股价反应 |
Amazon |
2000 亿美元 |
+56% |
持平 / -1.2% |
Alphabet |
1800 亿美元 |
+98% |
持平 / +0.5% |
Meta |
1250 亿美元 |
+74% |
持平 / -0.8% |
Microsoft |
1400 亿美元 |
+59% |
持平 / -2.1% |
垂直整合的威胁:谷歌TPU
对英伟达(NVIDIA)主导地位构成的最显著威胁来自谷歌(Google)的张量处理单元(TPU)。谷歌已成功证明,其在处理最关键的内部工作负载时可以绕过英伟达。目前,Gemini 3 和 4 几乎完全(95-100%)在谷歌内部 TPU 上进行训练,而英伟达 GPU 实际上仅处理该特定工作负载的 0-5%。对于搜索和 YouTube 等内部推理任务,TPU 仍处理约 85-90% 的业务量。
这种转变引发了投资者的叙事转变:如果 AI 模型领域的领导者正趋于脱离英伟达,其他人会效仿吗?然而,将谷歌视为两个独立实体时,现实情况更为复杂。虽然“谷歌内部”实现了自给自足,但“外部谷歌云”仍严重依赖英伟达来满足其客户需求。外部客户在约 60-65% 的工作负载中继续首选英伟达 GPU,很大程度上是因为谷歌 TPU 可能不符合其特定的架构需求,或者是因为他们被锁定在 CUDA 软件生态系统中。
工作负载类型 |
谷歌 TPU 处理比例 |
英伟达 GPU 处理比例 |
内部 AI 训练 (Gemini 3/4) |
~95% - 100% |
~0% - 5% |
内部 AI 推理 (搜索/YouTube) |
~85% - 90% |
~10% - 15% |
外部谷歌云 (客户租赁) |
~35% - 40% |
~60% - 65% |
AI CPU 的崛起与 AMD 的竞争
随着人工智能产业趋于成熟,重心正在从模型训练转向“推理”——即运行训练好的模型来回答用户查询。在这一新阶段,中央处理器(CPU)正重新获得重视。与需要图形处理器(GPU)原始并行计算能力的训练不同,推理通常涉及“分支”逻辑,即一系列快速的“如果/那么”决策,而CPU在处理这些决策方面更具优势。
这一转变对AMD有利,与NVIDIA的“Grace”或“Vera”产品相比,AMD的CPU在独立运作时通常被认为性能更强且更具成本效益。在当前市场上,许多外部云客户采用“混合”方案:将NVIDIA GPU与AMD CPU搭配使用。AMD提供的这种“点餐式”商业模式与NVIDIA的“套餐”模式形成鲜明对比,后者试图将GPU和CPU作为高度集成的整套方案进行销售。
NVIDIA的目标是通过证明其自研CPU(如Vera型号)在其生态系统内的表现优于第三方AMD Venice CPU,从而打破这种混合趋势。虽然AMD在“原始逻辑”和IPC(每时钟周期指令数)方面表现更佳,但NVIDIA的Vera CPU通过其基于ARM的架构提供了极高的能效,并针对人工智能专用软件进行了高度优化。
|
首选GPU |
首选CPU |
Google内部使用 |
Google TPU |
Google Axion |
Google外部客户 |
Nvidia GPU |
AMD CPU |
网络业务:英伟达的秘密武器
NVIDIA护城河的真正实力在于一个常被忽视的细分领域:网络。网络业务目前约占数据中心总收入的15%,即约82亿美元,同比增长达惊人的162%。这是NVIDIA的“秘密武器”,因为它在CPU和GPU之间架起了竞争对手难以复制的桥梁。
例如,当客户将AMD CPU与NVIDIA GPU搭配使用时,会受限于PCIe 6.0的连接速度,其上限为128 GB/s。然而,当使用全NVIDIA技术栈(Vera CPU和Rubin GPU)时,专有的NVLink 5.0网络设备可实现1,800 GB/s的速度——比标准连接快14倍以上。
指标 |
AMD EPYC "Venice" |
NVIDIA "Vera" CPU |
原生CPU逻辑 |
胜出者(更高的IPC / x86) |
良好(ARM Neoverse) |
CPU至GPU速度 |
128 GB/s (PCIe 6.0) |
1,800 GB/s (NVLink) |
能效 |
高 |
极高(ARM) |
软件选择 |
开放(可运行任何程序) |
封闭(针对AI优化) |
这种性能差异是NVIDIA用来劝说客户放弃AMD CPU的主要催化剂。如果整个系统的速度成为瓶颈,AMD CPU的“原生逻辑”优势就变得无关紧要。最近的动向,如Meta大量采购NVIDIA CPU,表明这种通过网络集成来扩展CPU业务的长期战略已开始生效。
结论
NVIDIA不再仅仅是一家芯片制造商,而是一家全系统供应商。虽然“GPU之战”在几年前就已尘埃落定,但“AI CPU之战”才刚刚拉开帷幕。市场目前的怀疑情绪反映了这样一种担忧:随着行业向推理和定制芯片转型,NVIDIA将无法继续掌握定价权或维持其主导地位。然而,通过将GPU、CPU和高速网络整合到一个封闭且优化的生态系统中,NVIDIA正在构建一道竞争对手难以通过“拼凑式”组件逾越的护城河。在即将举行的财报电话会议上,首席执行官黄仁勋(Jensen Huang)很可能会强调,这种全栈主导地位是其在竞争日益激烈的情况下维持75%利润率的关键。
交易商排行
- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管93.87
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.66
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管84.90
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照77.92
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管63.65
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.06
- 监管中markets4you毛里求斯监管| 零售外汇牌照| 主标MT4| 全球展业|74.61
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.51